Database type
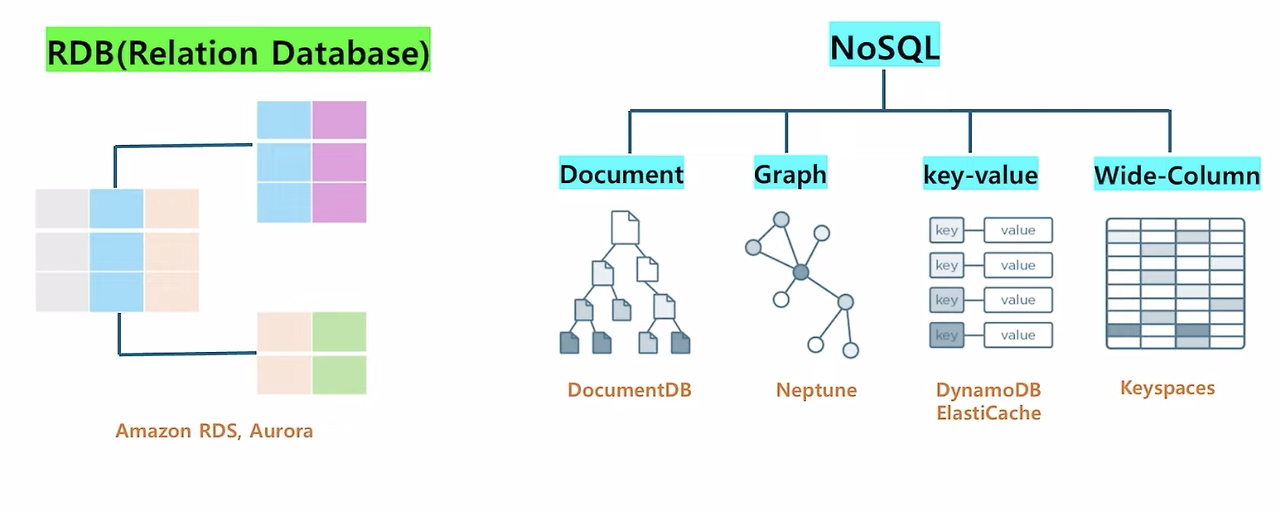
- RDB
- 전통적인 데이터베이스
- 관계형 데이터베이스, 테이블간의 join을 통해 데이터 결합
- AWS → Amazon RDS, Aurora DB
- NoSQL
- RDB보다 유연한 스키마 구조
- json, xml와 같은 documnet들을그대로 데이터베이스로 사용 가능
- AWS → Document DB
- mongoDB와 호환
- 노드 간의 관계를 나타내는 데에 강점이 있는 DB
- 소셜네트워크에서 많이 사용
- AWS → Neptune
- 고속으로 처리하기 위한 데이터베이스
- AWS → DynamoDB, ElasticCache
- 한 행별로 콜럼이 다 다를 수 있음 → 유연한 사용 가능
- AWS → Keyspaces
- 원장 DB (Ledger Database)
- 저널이라는 것을 갖고 있어, 들어오는 트랜젝션에 대한 이력관리가 가능
- 저널은 추가만 되고 삭제가 안된다. → 변경 이력 관리에 신뢰성을 보장한다.
- 변경 이력이 중요한 은행, 보험거래 등에 많이 사용된다.
- Amazon Quantum Ledger Database
- DW(Datawarehouse)
- 여러 가지 데이터 소스들에서 오는 데이터를 한 곳의 창고형식으로 모아서, 이 데이터를 분석하고 활용할 수 있도록 도움을 주는 창고형 데이터 저장ㅇ소
- Amazon Redshift

+) Aurora → 읽기 전용 / DynamoDB → 읽기 및 쓰기 모두 제공
RDB(Relation Database)
관계형 데이터베이스
- 관계형 데이터베이스에서 행(row)를 가리키는 또다른 말 = 레코드, 튜블
- 모든 관계형 데이터베이스의 테이블에 포함되어 있는 것 → 속성
- 테이블은 최소 하나 이상의 속성 또는 Column을 지니며, 기본키와 외부키는 다른 테이블의 데이터를 연관지을 때 사용되지만 필수요소는 아니다.
- 데이터 조회 명령어 → SELECT
- 데이터 저장 명령어 → INSERT
OLTP 온라인 입출력 처리 vs OLAP 온라인 분석 처리
- OLTP (Online Transaction Processing)
- 데이터의 빈번한 읽기 및 쓰기 작업이 요구되는 애플리케이션에 적합
- e.g. 분단 수백건의 주문을 처리하는 온라인 주문 시스템 등에 주로 사용
- 신속한 쿼리 작업에 최적화
- 정형화된 쿼리 주로 사용
- 충분한 메모리 용량을 갖는 단일 서버를 통해 모든 쓰기 및 읽기 작업을 처리한다.
- OLAP (Online Analytic Processing)
- 대규모 데이터에 대한 복잡한 쿼리 작업에 적합
- 높은 수준의 컴퓨트 및 스토리지 성능이 요구된다.
- 데이터 웨어하우스 애플리케이션의 경우 단일 OLAP 데이터베이스에 다수의 OLTP 데이터베이스를 결합해 사용
- e.g. 흩어져있는 OLTP 데이터베이스를 OLAP 데이터베이스의 하나의 테이블에 집약해 데이터 접근 가능
- 고성능의 OLAP에 복잡한 쿼리 작업을 분삲마으로써 데이터 처리 및 분석에 소요되는 시간을 단축시킬 수 있다.
데이터베이스 엔진
- 데이터베이스 엔진이란, 데이터베이스에 데이터를 저장, 조직화, 인출하는 소프트웨어이며, 각 데이터베이스 인스턴스는 오직 하나의 데이터베이스 엔진만 실행한다.
- RDS가 제공하는 6가지 엔진
- MySQL
- 블로그, 커머스 등 OLTP 애플리케이션에 적합
- InnoDB 사용
- MariaDB
- MySQL의 대체품
- InnoDB 사용
- Oracle
- 가장 널리 사용되는 DBMS
- Standard Edition One (SE1), Standard Edition Two(SE2), Standard Edition(SE), Enterprise Edition(EE) 제공
- Bring-Your-Own-License (BYOL) 모델로 사용할 수 있다.
- 사용자의 라이선스를 등록할 수 있도록 하는 서비스(사용자 보유 라이선스 활용)
- PostgreSQL
- Oracle 호환 오픈소스 데이터베이스
- Amazon Aurora
- Amazon이 제공하는 MySQL, PostgreSQL의 대체품
- 스토리지의 쓰기 횟수를 감소시키는 가상화 스토리지 레이어를 이용해 더 높은 수준의 쓰기 성능 제공
- MySQL 호환형, PostgreSQL 호환형 제공
- Microsoft SQL Server
- Express, Web, Standard, Enterprise 에디션 중 선택가능
- 기존 온프레미스 데이터베이스를 별도의 작업 없이 RDS로 이전할 수 있다.
- MySQL
- MySQL 호환 → MySQL, MariaDB, Amazon Aurora
RDB - Amazon RDS(Relational Database Service)
What is Amazon RDS?
- 관계형 데이터베이스를 지원하는 AWS 서비스로, EC2 인스턴스를 사용한다.
- EC2와 마찬가지로 러닝타임에 대해 요금이 부과되는 형식
- 데이터베이스를 구축하기 위해서는 Database Software, Storage, Infrastructure 등을 관할을 해야하는데, RDS를 사용하면 Infrastructure 에 대해서는 AWS에서 대신해줌
- RDS에서 서포트하는 데이터베이스 엔진 → MySQL, PostgreSQL, MSSQL, Oracle, and Aurora
RDS - Multi AZs Instance Deployment
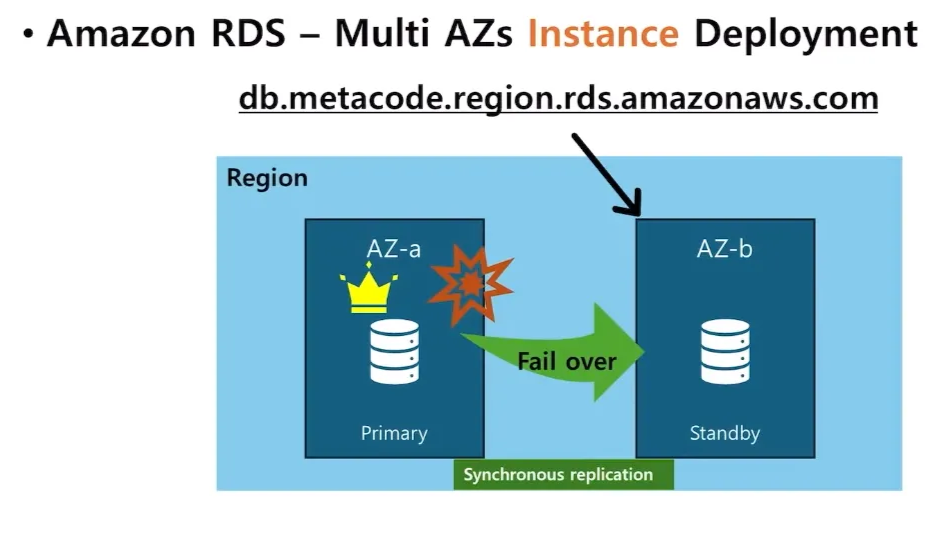
- RDS는 고가용성을 보장하기 위해 멀티 AZ 배포를 지원
- 하나의 리전에 다른 가용영역을 두어, RDS instance 를 복제해둘수 있다.
- 복제해둔 인스턴스를 Standby 인스턴스, 기존에 있던 인스턴스를 Primary 인스턴스라고 한다.
- RDS를 접속할 때는 도메인 네임으로 접속하게 된다. (db.metacode.region.rds.amazonaws.com)
- 해당 도메인네임이 장애가 발생하기 전에는 프라이머리 인스턴스를 바라보게 되어있지만, 해당 프라이머리 인스턴스가 있는 가용영역(AZ-a)에 장애가 발생 → 자동으로 스탠바이 인스턴스가 있는 가용영역(AZ-b)으로 도메인이 바라보도록 한다.
- ⇒ fail-over(장애가 발생했을 떄 자동으로 실행된다.)
- Prmiary와 standby는 Multi AZs Instance Deployment 에서는 동기적으로 복제된다.
- failover가 되면 standby가 primary가 되고, primary가 standby가 된다.
- 스탠바이에서는 read나 write를 지원하지 않는다.
- 인스턴스 배포에서는 한 대만 작동을 한다.
RDS - Multi AZs Cluster Deployment
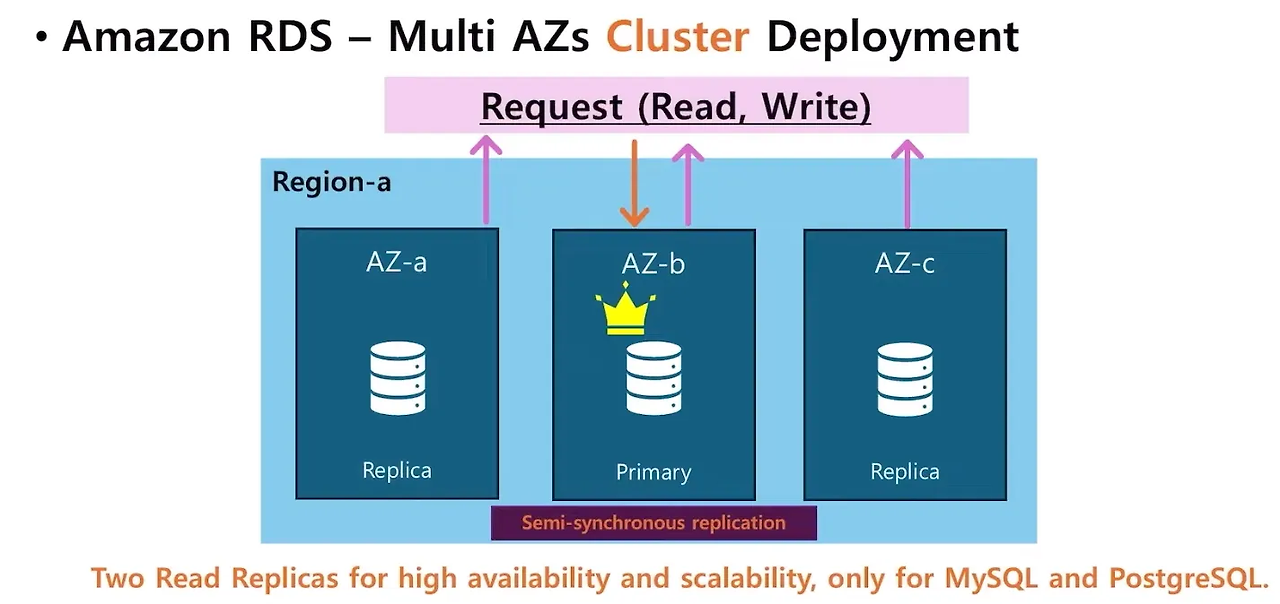
- 인스턴스 배포 - 클러스터 복제방식
- 프라이머리 인스턴스(AZ-b) 하나에 복제본 두 개(AZ-a,c)를 두는 것
- 프라이머리에서는 read, write가 가능하지만 복제본인 Replica에서는 read만 가능
- 두 읽기 전용 Replica는 높은 가용성과 확장성을 위해 사용된다.
- 준동기적으로 복제(Semi-synchronous replication)가 이루어지고, MySQL과 PostgreSQL에서만 제공
RDS - Read Replica
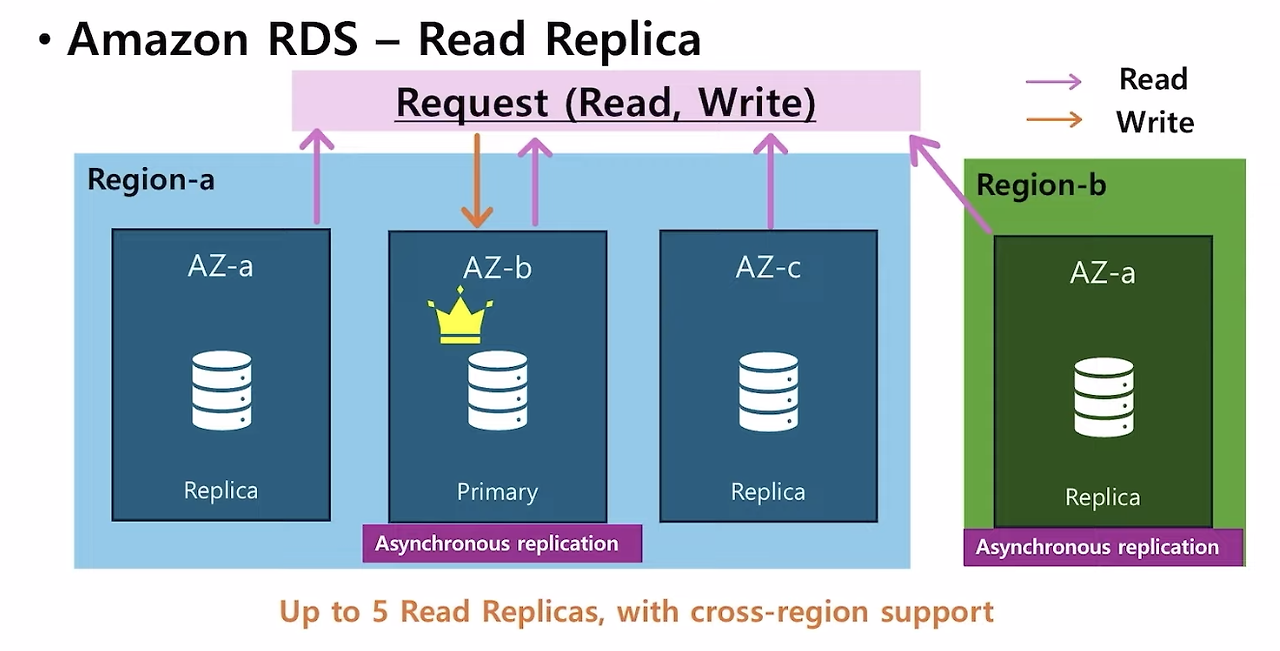
- RDS는 읽기 성능을 향상시키기 위해 read replica를 둔다.
- multi AZ와 비슷한 방식인데, read replica는 최대 5개 까지 복제가 가능하다. 다른 AZ에 배포가 가능하고, cross-region도 서포트한다.
- 프라이머리 인스턴스에서는 read, write가 가능하고, 다른 replica 인스턴스에서는 read만 가능하다.
- 비동기적으로 인스턴스가 복제(Asynchronous replication)된다.
- Read Replica도 재해복구 시스템으로 사용할 수 있다
- Read Replica는 ‘비동기식 복제’
Multi-AZ Instance vs Multi-AZ Cluster vs Read Replica
|
|
Multi-AZ Instance
|
Multi-AZ Cluster
|
Read Replica
|
|
구분
|
Primary(1) - Standby(1)
|
Primary(1) - Replica(2)
|
Primary - Replica(5)
|
|
Primary
|
Read / Write
|
Read / Write
|
Read / Write
|
|
Standby or Replica
|
X
|
Only Read
|
Only Read
|
|
cross region 가능
|
불가능
|
불가능
|
가능
|
|
fail-over
|
가능
|
불가능
|
불가능
|
|
복제 방식
|
동기적으로 인스턴스 복제 (Synchronous)
|
준동기적으로 인스턴스 복제 (Semi-synchronous)
|
비동기적으로 인스턴스 복제 (Asynchronous replication)
|
|
목적
|
고가용성
|
고가용성, 확장성
|
고가용성, 확장성
|
RDS - backup
- 기본적으로 7일 자동 백업, 특정 시점의 구분으로 복구가 가능하다
- retention time 기간은 35일로, 35일 이상의 데이터를 보관하고자 한다면 비용 효율을 위해 S3에 저장하는 것을 추천한다
- 좀 더 긴 백업의 경우에는 AWS Backup 서비스를 활용하는 것을 추천한다.
RDS Custom
- RDS Custom은 기존 운영체제에 대한 액세스를 유지한다.
- Oracle → RDS Custom for Oracle(Custom Engine Version)
- 사용 예시
- 온프레미스 환경에서 운영 라이센스를 구입해 운영중이던 Oracle을 AWS 환경으로 그대로 가져올 경우, Oracle 라이센스를 AWS에서 그대로 사용할 수 있다.
RDS 인스턴스 암호화
- RDS 인스턴스는 생성 시에만 암호화 활성화가 가능하다
- 암호화된 RDS 인스턴스
- DB 저장소, 자동백업, DB 스냅샷, 리전 간 복제본을 자동으로 암호화
- 모든 데이터가 KMS 키로 암호화된다.
- 암호화되지 않은 RDS 인스턴스
- 모든 데이터가 암호화되지 않음
- 암호화된 RDS 인스턴스
- 암호화된 스냅샷을 사용한 데이터베이스 복원
- RDS에서 암호화되지 않은 스냅샷을 AWS KMS 키를 사용하여 암호화된 스냅샷으로 복사
- 암호화된 스냅샷에서 새 데이터베이스 인스턴스 복원
- 복원된 데이터베이스는 암호화된 상태로 생성됨
- 복원 시 사용하는 KMS 키를 기반으로 데이터를 보호한다.
- 이후 해당 데이터베이스에서 생성되는 백업과 스냅샷도 자동으로 암호화된다.
RDB - Amazon Aurora
What is Amazon Aurora
- RDS와 가장 많이 비교되는 RDB Database, 관계형 데이터베이스를 지원한다.
- AWS에서 직접 구축한 데이터베이스
- RDS와의 차이점
- RDS는 mySQL, PostgreSQL와 같은 엔진을 제공하는 것
- AWS Amazon Aurora는 오로라 데이터베이스가 하나의 데이터베이스 엔진으로 보면 된다. mysql이나 postgre와 같은 엔진을 변환 없이 AuroraDB에 그대로 바로 사용할 수 있다.
- 오로라 Database는 DB Cluster로 관리되는 서비스이며, 데이터베이스에 연결된 스토리지가 6개의 카피로 3개의 AZ에 걸쳐서 저장이 되므로 높은 가용성을 갖는 아키텍처
- PostgreSQL 데이터베이스를 Amazon Aurora로 마이그레이션
- Aurora는 관리형 데이터베이스 서비스로, 자동 확장, 백업, 고가용성을 제공하여 운영 오버헤드를 줄임.
- 데이터베이스 관리와 확장을 간소화할 수 있음.
Amazon Aurora - Multi AZs
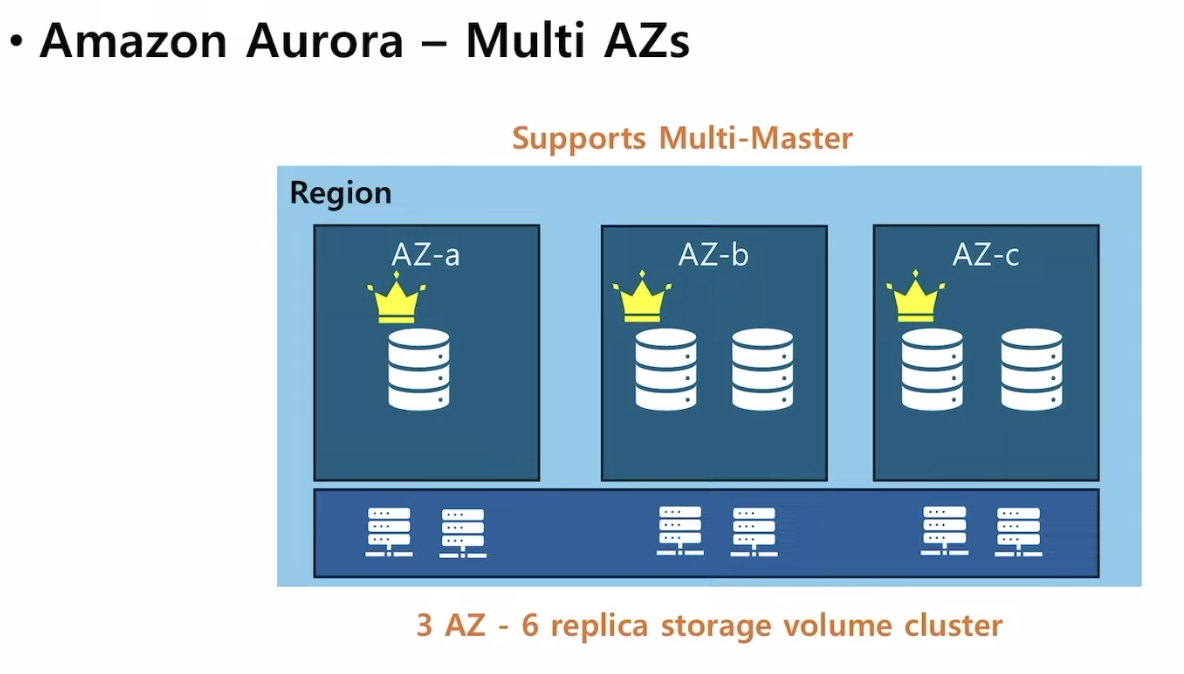
- 아마존 오로라 데이터베이스에 연결된 스토리지는 클러스터링되어있어서 공유되어있는 형식
- 3개의 AZ에 걸쳐서 저장되어 있고, 복제되어 있다.
- 오로라 데이터베이스는 여러개의 프라이머리 인스턴스를 가질 수 있다. (= Multi Master를 지원한다.)
Amazon Aurora - Read Replica
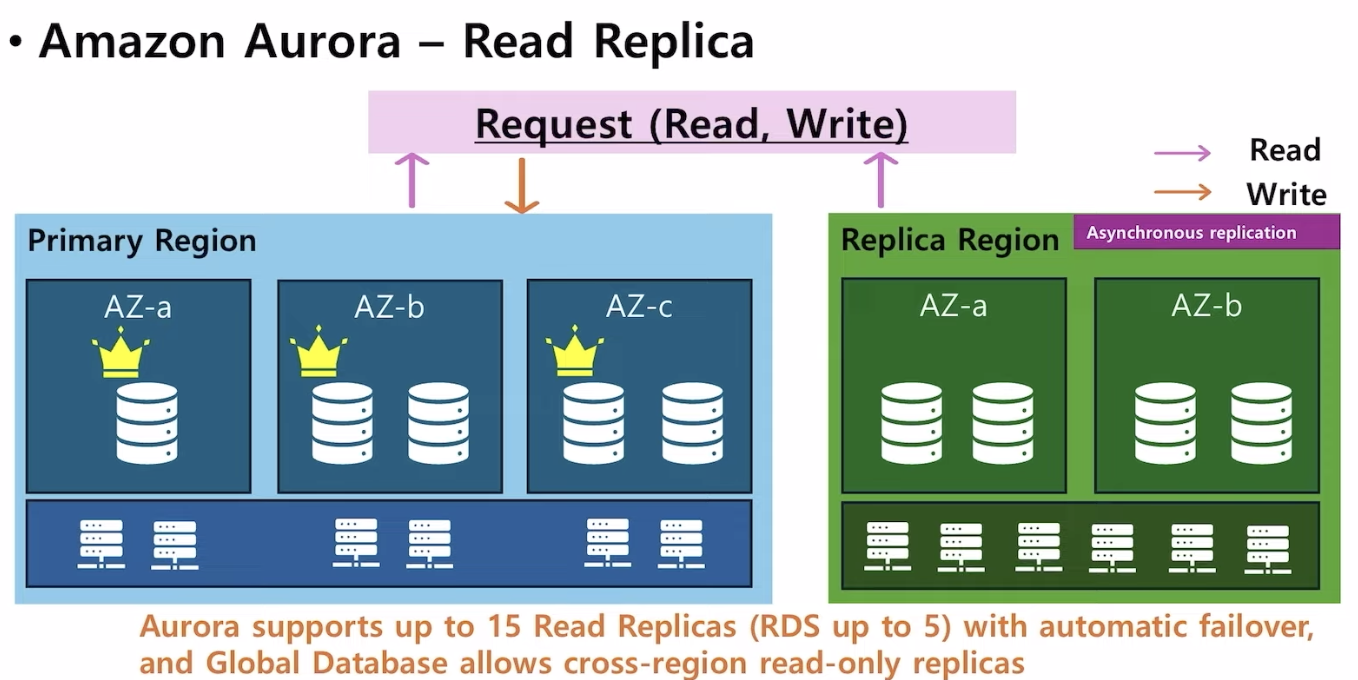
- Read 성능 향상을 위해, Aurora는 최대 15개의 read replica를 가질 수 있다. (RDS는 최대 5개까지 read replica를 가질 수 있다.)
- read replica는 자동으로 failover 될 수 있다.
- read replica는 다른 리전에도 복제될 수 있다. 이때 primary instance를 둘 수 없고, replica instance만 둘 수 있다 → Replica region에서는 read만 가능하다
|
|
Aurora Multi-AZ
|
Aurora Read Replica
|
|
구조
|
3개의 AZ에 걸쳐서 저장되고 복제됨
|
최대 15개의 Read Replica 지원 (RDS는 최대 5개)
|
|
자동 fail-over
|
지원 X
|
지원 O
|
|
Multi Master
|
여러개의 프라이머리 인스턴스 가능
|
여러개의 프라이머리 인스턴스 가능
|
|
Cross-region
|
지원 X
|
지원 O, Replica Region에서는 only Read
|
Amazon Aurora Backup
- 세 개의 AZ에 걸쳐서 복제되어있기 때문에, 자동 복구를 지원한다.
- DB Snapshot의 경우 최대 5분 전까지 저장을 하고있다. → 5분전의 내용을 바로 복구할 수 있다.
Amazon Aurora Serverless
- Aurora를 서버리스 형태로 사용 → 오로라데이터베이스의 사용양을 당장 모를 때
- 인스턴스 사이즈를 지정해놓지 않아도 된다는 장점
- 오로라를 도입하기 전에, 새로운 신규서비스를 런칭헀을 때 사용할 수 있다.
Amazon RDS Proxy
1. 개념
- Amazon RDS Proxy는 Amazon RDS와 Amazon Aurora 데이터베이스를 위한 관리형 데이터베이스 프록시 서비스입니다.
- Lambda 함수, 컨테이너 기반 애플리케이션 또는 EC2 인스턴스에서 사용하는 데이터베이스 연결을 효율적으로 관리하여 데이터베이스의 성능과 확장성을 높이고, 가용성을 향상시킵니다.
2. 주요 특징
1. 연결 풀링 (Connection Pooling)
- 짧은 수명의 많은 데이터베이스 연결을 미리 생성한 연결 풀에서 재사용.
- 연결 생성/종료로 인한 데이터베이스의 부하를 감소.
- 애플리케이션이 동시 실행 시 많은 연결을 생성하는 워크로드에 적합. → 데이터베이스에 대한 병목현상 해결 가능
2. 가용성 향상
- RDS Proxy는 데이터베이스 장애 시 자동 장애 조치(Automatic Failover)를 지원.
- 데이터베이스 장애 조치 중 연결을 유지하여, 애플리케이션이 중단 없이 동작.
3. 보안 통합
- AWS Identity and Access Management (IAM)과 통합되어 보안 자격 증명 관리.
- Amazon Secrets Manager와 연계하여 데이터베이스 자격 증명을 안전하게 저장 및 교체 가능.
4. 성능 최적화
- 데이터베이스의 연결 수를 최적화하여 CPU 및 메모리 사용량 감소.
- 데이터베이스가 동시 연결 처리 제한을 초과하지 않도록 보호.
3. 동작 원리
- 애플리케이션 요청:
- Lambda 함수 또는 EC2 인스턴스가 데이터베이스 요청을 RDS Proxy로 보냄.
- RDS Proxy 처리:
- RDS Proxy는 데이터베이스에 대한 연결을 관리.
- 연결 풀을 유지하여 기존 연결을 재사용하거나 필요 시 새 연결 생성.
- 데이터베이스 응답:
- RDS Proxy는 데이터베이스의 응답을 애플리케이션으로 전달.
4. 주요 사용 사례
1. 서버리스 애플리케이션 (AWS Lambda와 연계)
- Lambda 함수는 짧은 수명의 연결을 반복적으로 생성하므로, 데이터베이스 부하가 높아질 수 있음.
- RDS Proxy를 사용해 Lambda 함수와 데이터베이스 간 연결을 최적화.
2. 컨테이너 기반 애플리케이션 (Amazon ECS/EKS)
- 여러 컨테이너가 동시에 데이터베이스 연결을 요청할 경우 연결 폭주 발생 가능.
- RDS Proxy가 연결 풀을 관리해 데이터베이스 연결을 효율적으로 사용.
3. 고가용성 및 장애 조치 (Failover)
- Amazon Aurora 또는 RDS Multi-AZ 구성과 함께 사용해 데이터베이스 장애 시 자동으로 장애 조치.
- 애플리케이션 연결을 유지하여 중단 없는 서비스 제공.
NoSQL
NoSQL - Amazon Document DB
What is Amazon Document DB?
- Document DB → json, xml과 같은 반정형 데이터를 바로 데이터베이스로 쓸 수 있는 서비스 (document-oriented database service)
- documentDB인 MongoDB가 Amazon document DB에 호환된다.
- JSON 형식으로 데이터를 저장하기 때문에, JSON의 모든 요소 내에서 포괄적인 검색이 가능하다.(Key-value 방식에서는 기본키로만 검색이 가능하다)
- 효율적인 쿼리 기능을 갖춘 유연하고 풍부한 데이터 모델이 필요한 애플리케이션에서 이상적이다.
NoSQL - Amazon Neptune
What is Amazon Neptune
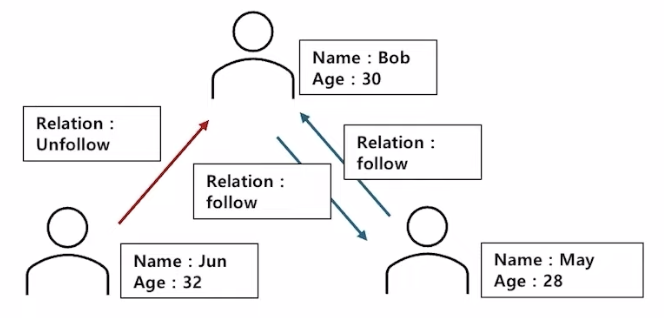
- graph databaseDB
- 관계를 나타낼 때 유용하게 쓰이는 데이터베이스로, 각 노드에는 노드가 갖는 property가 존재하고 노드 간의 relation 관계에도 property가 존재한다.
- node는 사물, relation은 그들의 관계, property는 relation과 node 간에 정의되어있는 column들을 의미한다.
- Process change를 감지할 수 있다.
+) Amazon Kinesis Data Streams?
- Amazon Kinesis는 스트리밍 데이터의 수집, 처리, 저장, 전송을 위한 서비스 모음이며, 대용량 스트리밍 데이터를 처리할 수 있다. (e.g. clickstream data)
- Neptune Streams에 비해 오버헤드가 크다.
NoSQL - DynamoDB
What is Amazon DynamoDB
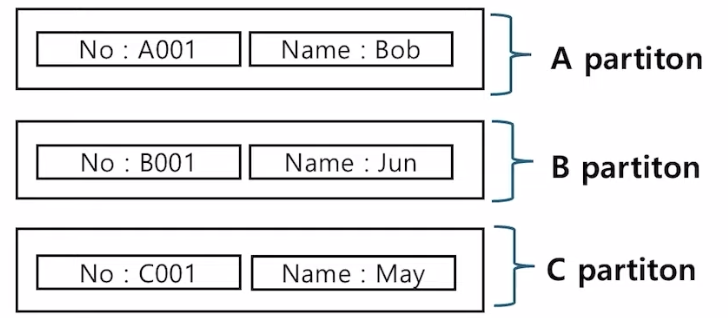
- aws에서 가장 많이 사용되는 데이터베이스
- Key-Value database 서비스를 지원한다.
- Lambda와 같이 event-driven service를 같이 연계해서 사용한다.
- 각각의 item들이 partition key를 통해 partition되어있고, partition들은 가용성을 위해 3개의 AZ에 복제되어있다.
Partition Key, Sort Key
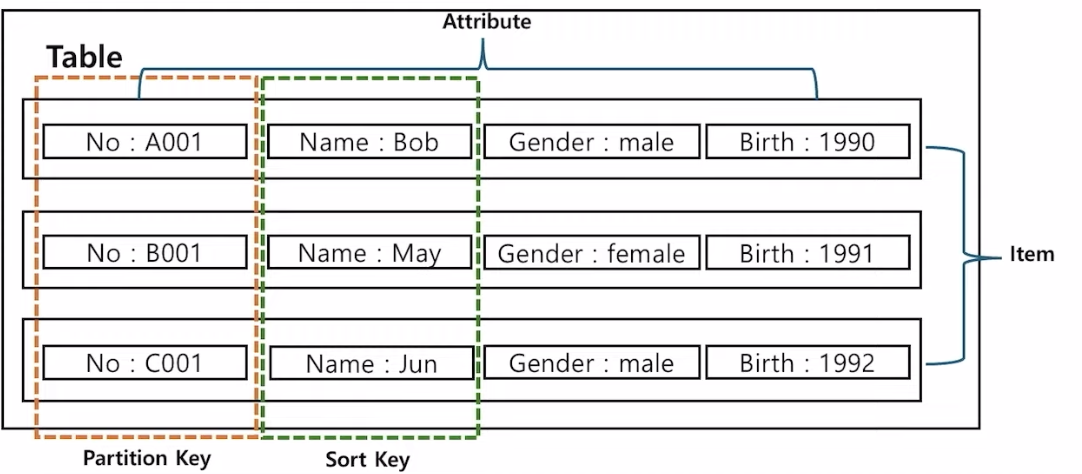
- 전체를 하나의 테이블로 보면,
- 하나의 행(row)들 → 아이템
- 아이템 안의 column들 → attribute(속성)
- Partition Key
- Hash 값으로 인덱싱 되고, 정렬이 되어있지는 않다.
- 파티션 키를 하나만 사용했을 때는 프라이머리 키처럼 유니크한 값으로 사용되므로, 충분한 cardinality를 가져야한다.
- RDB에서의 primary 키 역할
- e.g. Number
- Sort Key
- partition 키와 함께 사용되는 키, 파티션 키와 같이 연결되어서 유니크한 키로서 사용될 수 있다.
- 정렬하는 역할
- 카산드라의 Column 키와 유사한 역할
- e.g. Name
Capacity Unit (RCU, WCU)
- DynamoDB에서 쓰이는 단위로, 과금을 할 때 사용된다.
- RCU = Read Capacity Unit
- 1 RCU = Read를 1초당 4KB
- WCU = Write Capacity Unit
- 1 WCU = Write를 1초당 1KB
- Provisioned
- 잘 사용하고있고, 사용량을 어느정도 판단할 수 있는 경우에는 프로비전드 과금체계를 이용하여 RCU와 WCU를 미리 할당해놓는 과금체계 (좀 더 저렴하게 사용 가능)
- On-demand
- 사용량을 가늠하기 어려울 때는 온디맨드 방식을 사용한다.
- 실제 사용한 read, write 사용량만큼 지불한다.
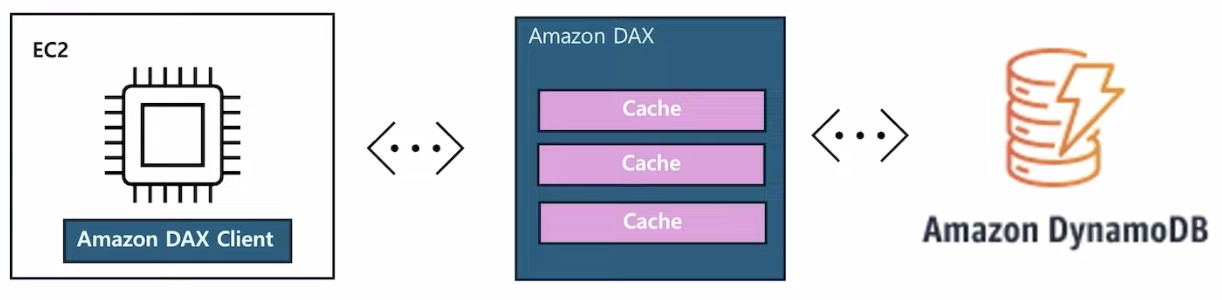
What is Amazon DAX (DynamoDB Accelerator)?
- DynamoDB는 굉장히 빠른 Key-Value 서비스인데, 이런 DynamoDB를 캐싱하여 좀 더 빠르게 사용하는 서비스 ⇒ 읽기 작업을 최적화(쓰기작업 최적화는 아님)
- 예를 들면 EC2 서버에 아마존 DAX 클라이언트를 설치한 후, 아마존 DAX가 이 클라이언트와 연동하여 캐싱을 한다.
- ⇒ EC2와 DynamoDB 사이에 연결되어 좀 더 빠른 성능을 보여줄 수 있도록 한다.
- DAX 는 장애 탐지, 장애 복구, 소프트웨어 패치와 같은 일반적인 관리 작업 상당 부분을 자동화
지정시간복구
- DynamoDB 테이블에 대한 특정 시점 복구를 활성화
- 지정 시간 복구는 우발적인 쓰기 또는 삭제 작업으로부터 테이블을 보호하는 데 도움
- 특정 시점 복구 → 지난 35일 동안의 특정 시점으로 테이블 복구 가능
NoSQL - Amazon Elasticache
What is Amazon Elasticache?
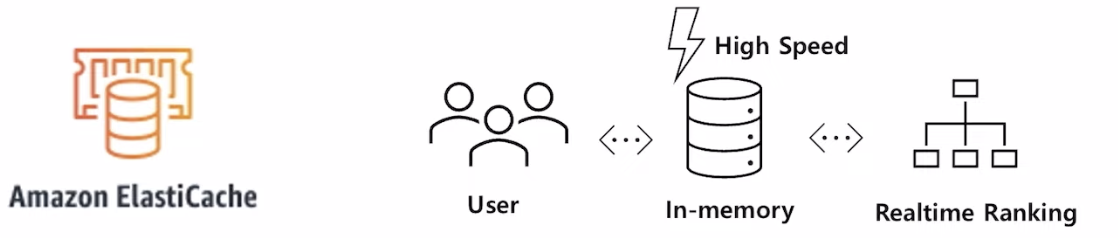
- In-memory Key-Value 데이터베이스
- 장점 : 엘라스틱 캐시는 SSD나 HDD까지 가지 않고도, 메모리 위에서 Key-Value 서비스를 제공하여 read/write를 좀 더 고속으로 사용할 수 있다.
- 단점 : 메모리는 휘발성이기 때문에 인스턴스가 내려가면 데이터가 다 지워지는 단점
- ⇒ 지속적인 데이터 저장이 필요없는, 단기성으로 사용할 수 있는 데이터베이스 설계에 적합하다. (e.g. 세션 스토리지, 스트리밍 등)
- 호환되는 데이터베이스 → Redis, Memcached
- Redis는 세션 데이터 저장에 적합하며, 다중 AZ 배포로 고가용성을 보장할 수 있음
- 빠른 데이터 접근에는 도움이 되지만, 가용성과 내구성에는 영향이 없다.
NoSQL - Amazon Keyspaces
What is Amazon Keyspaces?

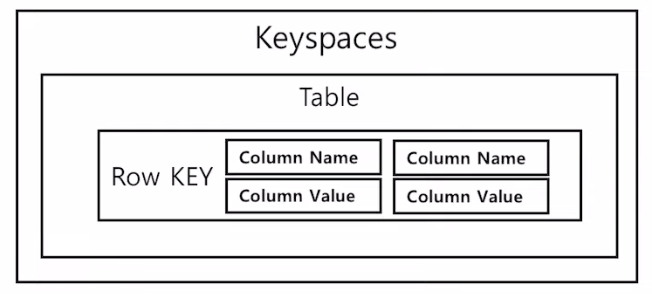
- 아마존 키스페이스 → 아파치 카산드라 데이터베이스를 지원하는 AWS 서비스
- 아파치 카산드라 데이터베이스는 Wide Coulumn format 형식으로 지원되는 NoSQL 데이터베이스
- Wide Coulumn format에서는 한 행 별로 각각 다른 칼럼을 가질 수 있다 → 좀 더 유연한 스키마
- 아파치 카산드라를 서버리스 형태의 서비스로 지원하는 것이 아마존 키스페이스 서비스
Ledger Database
Ledger Database - Amazon Quantum Ledger Database
원장(Ledger)이란?원장은 일반적으로 특정 거래나 데이터 포인트를 쉽게 찾아 볼 수 있는 방식으로 구성되며, 상품이나 자산의 이동을 회계, 감사, 추적하는 등 다양한 용도로 사용될 수 있다.
원장(Ledger)은 금융 거래나 다른 유형의 데이터를 추적하는 데 사용되는 기록 보관 시스템이다.
What is Amazon Quantum Ledger Database?

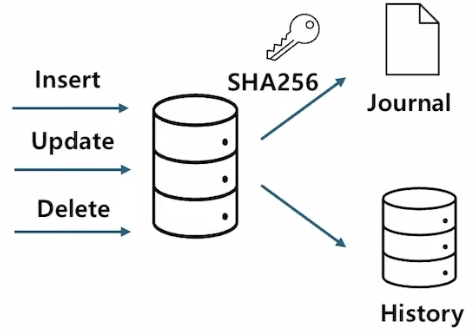
- 원장 데이터베이스는 변경 이력이 중요한 데이터 구조에 사용되는 데이터베이스
- 변경 이력은 SHA-256 암호화를 통해서 간결한 요약을 생성한다. 간결한 요약을 ‘다이제스트’라고 하는데, 다이제스트는 변경 기록의 증거로 사용이 되며 저널에 저장이 된다.
- 다이제스트는 추가는 되지만, 변경 및 삭제는 불가능하다 → 높은 신뢰성을 보장한다.
- e.g. 은행 기록, 제조 이력, 보험 프로세싱에 사용
Data Warehouse
Data Warehouse - Amazon Redshift
What is Amazon Redshift?
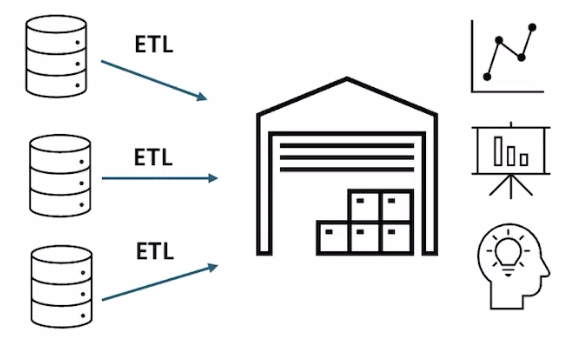
- 데이터웨어하우스 서비스는 각각의 다른 데이터소스를 하나의 창고같은 저장소에 저장하여 데이터 분석에 활용하는 서비스
- Redshift 에서는 S3, RDS에 저장된 데이터도 Redshift 를 통해 SQL로 분석 혹은 BI 툴로 전송해줄 수 있다.
- 일반적으로 데이터웨어하우스는 Column Storage Sturcture를 따른다.
'SAA-C03' 카테고리의 다른 글
| AWS Certification 자격증 등록번호 확인하는 방법 (Validation number) (0) | 2025.01.27 |
|---|---|
| [SAA-C03] 4. Networking and Content Delivery (2) | 2024.12.26 |
| [SAA-C03] 2. Storage (3) | 2024.12.20 |
| [SAA-C03] 1. Compute & Container & Serverless (3) | 2024.12.20 |
| [SAA-C03] 0. What is AWS? (0) | 2024.12.20 |